 |
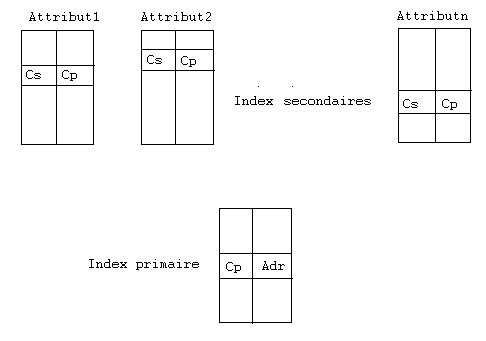
Organisation d'un index secondaire
Exemple de combinaison de clés secondaires
On désire récupérer
l'article d'un fichier qui a tel et/ou tel attribut. Par exemple, si l'article d'un
fichier bibliothèque possède les rubriques suivantes :
Référence, Titre, Année, Auteur
on peut vouloir faire les
requêtes du genre :
- retrouver tous les livres parus en 1973.
- retrouver tous les livres parus en 1973 de l'auteur X donné.
Une solution simple consiste à créer des index secondaires pour chaque attribut comme le montre la figure ci-dessous. Nous verrons plus loin pourquoi on ne met pas directement l'adresse de la donnée mais on passe toujours par l'index primaire.
|
![]()
Organisation d'un index secondaire
Essayons de voir maintenant comment on organise un index secondaire. Une première solution peut être la suivante :
 |
Une entrée d'un index secondaire est le couple (Cs, Cp) o?Cs est une clé secondaire et Cp la clé primaire qui lui est associée. Les clés secondaires sont dupliquées, ce qui peut rendre l'index volumineux.
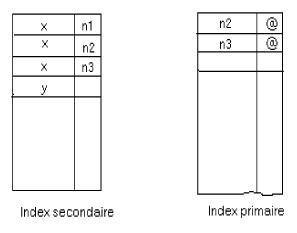
Afin de ne pas répéter les clés secondaires, une solution consiste à organiser l'index secondaire comme suit :
 |
C'est à dire par un tableau et donc un nouveau problème apparaît : c'est celui de la taille (nombre de clés primaires par clé secondaire)
![]() Une autre solution (et c'est la
meilleure) consiste à utiliser les "Listes inversées" comme le montre la figure suivante :
Une autre solution (et c'est la
meilleure) consiste à utiliser les "Listes inversées" comme le montre la figure suivante :
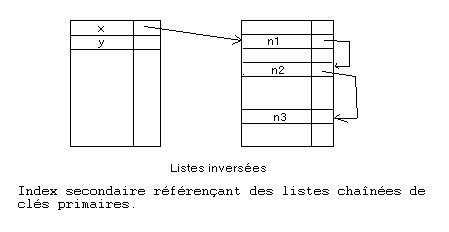 |
![]() On les appelle
ainsi car pour retrouver un article on commence par la fin c'est à dire : clé
secondaire, puis la clé primaire avant d'arriver à l'article lui-même.
On les appelle
ainsi car pour retrouver un article on commence par la fin c'est à dire : clé
secondaire, puis la clé primaire avant d'arriver à l'article lui-même.
![]()
Exemple de combinaison de clés secondaires
On veut récupérer les articles possédant l'attribut X et l'attribut Y. On suppose donc l'existence des index sur les champs X et Y. L'algorithme suivant permet de retrouver les articles en question :
L'index sur X donne
l'ensemble des clés primaires avec l'attribut X.
L'index sur Y donne l'ensemble des clés primaires avec l'attribut Y.
L'intersection donne l'ensemble des clés primaires ayant l'attribut X et Y. Pour chaque élément de cet ensemble, on fait alors un accès disque pour retrouver et lister l'article, après avoir bien entendu retrouvé son adresse dans l'index primaire.
![]()
Pourquoi passer par l'index primaire?
Le problème réside au niveau de l'opération de suppression. Essayons de voir comment supprimer un article de clé secondaire donnée ?
![]() Il faut l'enlever de tous les
index secondaires, donc les réarranger tous, ce qui est excessivement cher surtout s'ils
ne sont pas présents en mémoire centrale.
Il faut l'enlever de tous les
index secondaires, donc les réarranger tous, ce qui est excessivement cher surtout s'ils
ne sont pas présents en mémoire centrale.
Si on ne les supprime pas et si la clé référence directement la donnée, il est impossible de dire quelles sont les références non valides.
![]() La solution est donc de ne pas
toucher aux index secondaires(les clés secondaires référencent les clés primaires) et
ajouter un bit d'effacement au niveau de l'index primaire. Une recherche commence par
l'index secondaire, puis l'index primaire. Dans ce dernier, on s'aperçoit que la clé a
été effacée. D'o?l'intérêt de ne pas pointer directement la donnée à partir de
l'index secondaire.
La solution est donc de ne pas
toucher aux index secondaires(les clés secondaires référencent les clés primaires) et
ajouter un bit d'effacement au niveau de l'index primaire. Une recherche commence par
l'index secondaire, puis l'index primaire. Dans ce dernier, on s'aperçoit que la clé a
été effacée. D'o?l'intérêt de ne pas pointer directement la donnée à partir de
l'index secondaire.
![]()
1. Le fichier est un ensemble de blocs contigus 1, 2, ......N. A chaque article est associée une clé primaire qui l'identifie de façon unique. Les articles sont de longueur fixe. On convient de mettre B articles par bloc.
On considère deux index secondaires pour l'attribut X et Y de l'article. Ces index sont organisés sous forme de "listes inversées". Les fichiers d'index sont ordonnés. Le fichier de données ne l'est pas.
Concevoir les algorithmes
de :
- chargement des fichiers d'index secondaire et
primaire.
- sauvegarde des fichiers d'index secondaire et
primaire.
- listage des articles de clé secondaire,
selon l'attribut X , donnée.
- listage des articles ayant une clé
secondaire, selon l'attribut X, donnée et une clé secondaire, selon l'attribut
Y, donnée.
- insertion d'un article ayant A comme
clé primaire, Ax et Ay comme clés secondaires selon les attributs X et
Y
respectivement.
- suppression d'un article de clé primaire
donnée.
![]()