Sommaire Définition du langage d’expérimentation Compilateur pour le langage Z minimal Extensions du langage Z minimal
Chapitre précédent Chapitre 9 : Sémantique des instructions Chapitre suivant
9.2 Table complémentaire (TABCOMP )
9.7 Synthèse sur la phase sémantique
9.1 Introduction
![]()
Trois types d’instructions existent dans le langage minimal : affectation, lecture, écriture. Il s’agit d’insérer les fonctions sémantiques quelque part dans les règles syntaxiques pour générer les quadruplets relatifs aux instructions.
Une lecture/écriture permet de lire/écrire plusieurs données/expressions à la fois( Exemples : LIRE(A, B,C, …) ; ECRIRE (A, B, I+5, ‘Compilateur’) ).
Comme un quadruplet ne suffit pas pour ranger tous les arguments des opérations de lecture ou écriture, nous utiliserons une table complémentaire : TABCOMP.
9.2 Table complémentaire (TABCOMP )
![]()
Pour les opérations de lecture et écriture, nous utilisons TABCOMP de la manière suivante:
- Ranger les arguments (indices vers les objets ) dans TABCOMP à partir du premier emplacement disponible dans cette table.
- Dans le quadruplet à générer il suffit de ranger l’emplacement du premier argument et le nombre d’arguments.
Nous verrons par la suite que TABCOMP est partagée par plusieurs types de quadruplets.
Un module est nécessaire sur la table complémentaire:
New_item_comp (Pointeur_objet)
Il ajoute une entrée dans TABCOMP et rend l’indice dans cette table où le pointeur de l’objet (Pointeur_objet) est rangé , -1 si échec.
Une limite (LimitTabcomp) est à définir sur cette table. On prendra une valeur arbitraire.
9.3 Quadruplets
![]()
Nous devons générer dans la phase sémantique les trois types de quadruplets suivants:
- Quadruplet de l’affectation : (‘Aff’, B, C , D ) ou (‘:=’, B, C , D )
B : pointeur dans TABOB vers le membre gauche de l’affectation.
C : non utilisé.
D : pointeur dans TABOB sur l’objet qui contient le résultat de l’expression du membre droit de l’affectation.
- Quadruplet de la lecture : (‘Lire’, B, C , D )
B : pointeur dans TABCOMP vers la liste des variables.
C : nombre de variables.
D : non utilisé.
Quadruplet de l’écriture : (‘Ecrire’, B, C , D )
B : pointeur dans TABCOMP vers la liste des variables contenant les résultats des expressions à écrire.
C : nombre de variables.
D : non utilisé.
9.4 Syntaxe des instructions
![]()
Afin de décrire la sémantique des instructions, nous rappelons d’abord leurs définitions syntaxique et sémantique puis nous montrons comment insérer les fonctions sémantiques dans les règles de grammaire avant de les décrire en détail.
Définition syntaxique
Les règles en surbrillance dénotent les instructions du langage Z minimal.
< Lis > → < Inst > { ; < Inst > }*
<Inst> → Idf := <Exp> | Lire ( Idf {, Idf }* ) | Ecrire (<Exp> {,<Exp>}* )
Définition sémantique
Le programme est un ensemble d’instructions. Une instruction peut être une affectation, lecture ou écriture. La définition sémantique de chaque instruction peut être formulée en langage naturel comme suit:
- Affectation
Une affectation permet d’attribuer la valeur d’une expression à une variable. Les deux membres du signe d’affectation doivent être de même type.
- Lecture
L’instruction de lecture permet d’introduire des données dans des variables. Les paramètres de l’opération LIRE doivent être des variables du même type que celles des données lues. De plus, aucune conversion n’est entreprise par le compilateur.
- Écriture
L’instruction d’écriture permet d’afficher les résultats. Les paramètres de l’opération ECRIRE ne peuvent être que des expressions de type scalaire (ENTIER pour le langage Z minimal).
9.5 Fonctions sémantiques
![]()
< Lis > → < Inst > { ; < Inst > }*
<Inst> → Idf := F7 <Exp> F8 | Lire ( Idf F4 {, Idf F5 }* ) F6 | Ecrire (<Exp> F1 {,<Exp> F2 }* ) F3
F1
Soit Temp le résultat de <Exp>.
Vérifier que le type de Temp peut être écrit. Ranger Temp dans TABCOMP. Soit Pt son emplacement dans TABCOMP.
Initialiser une variable Compte à 1.
F2
Soit Temp le résultat de <Exp>.
Vérifier que le type de Temp peut être écrit. Ranger Temp dans TABCOMP. Il est donc rangé à l’emplacement Pt + 1.
Incrémenter la variable Compte d’une unité.
F3
Générer le quadruplet (‘Ecrire’, Pt, Compte, ).
F4
Rechercher Idf dans la table des symboles pour récupérer l’objet correspondant dans TABOB (Soit Temp).
Vérifier que le type de Temp peut être lu.
Ranger Temp dans TABCOMP. Soit Pt son emplacement dans TABCOMP.
Initialiser une variable Compte à 1.
F5
Rechercher Idf dans la table des symboles pour récupérer l’objet correspondant dans TABOB (Soit Temp).
Vérifier que le type de Temp peut être lu.
Ranger Temp dans TABCOMP. Il est donc rangé à l’emplacement Pt + 1.
Incrémenter la variable Compte d’une unité.
F6
Générer le quadruplet (‘Lire’, Pt, Compte, ).
F7
Rechercher Idf dans la table des symboles pour récupérer l’objet correspondant dans TABOB (Soit Temp1). Il y a erreur si Idf est non trouvé (non déclaré).
F8
Soit Temp2 le résultat de <Exp>. Vérifier que les types de Temp1 et Temp2 sont les mêmes, sinon Erreur. Générer le quadruplet (‘Aff’, Temp1, , Temp2).
9.6 Exemple
![]()
La figure 11 montre les tables de compilation créées pour un programme source Z donné.
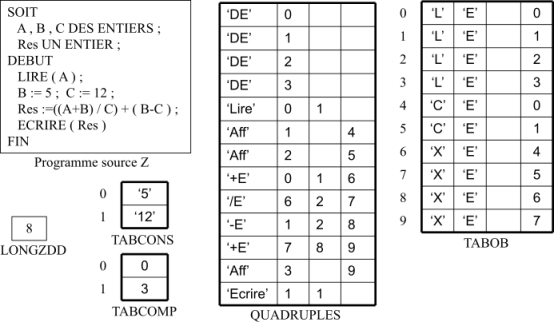
Figure 11: Tables de compilation (Instructions)
9.7 Synthèse sur la phase sémantique
![]()
Afin de simplifier l’écriture du compilateur, on a utilisé des tables. On peut utiliser diverses structures de données.
La forme intermédiaire choisie (quadruplet) est la forme la plus simple. On peut utiliser toute autre forme interne.
On n’a pas traité les optimisations. En général, elles se font sur le code intermédiaire généré. ( Exemple: pour chaque nouvelle expression, réutiliser les auxiliaires déjà utilisés ou bien au sein d’une même expression réutiliser certains auxiliaires ). On peut rajouter des programmes d’optimisation.
Pour des raisons de clarté, les fonctions sémantiques sont des modules séparés. Les appels de modules consomment de l’espace! On peut insérer directement les codes des modules.