Structures de données et de fichiers
|
Enoncé 3. Hachage interne - Fichiers structurés en tableaux Corrigé 3
Exercice 1 : Hachage ou rangement dispersé dans une table
Soit en mémoire centrale, un tableau de M cases. Chaque case peut renfermer B clés ( données ). Considérons la méthode de résolution de collisions dite d'adressage par essai linéaire (si la case I du tableau T[0..M-1] est remplie, on consulte les cases fournies par la séquence cyclique I-1, I-2, .......0, M-1, M-2,.. jusqu'à la rencontre d'une case ouverte, c'est à dire une case non remplie ).
1. Décrire la structure de données utilisée. Expliquer les différents champs.
2. Ecrire l'algorithme de recherche d'une clé donnée.
3. Ecrire l'algorithme d'insertion d'une clé donnée.
La suppression est faite par l'élimination physique de toute la clé de la case et le transfert éventuel d'une clé dans son adresse primaire.
4. Ecrire l'algorithme correspondant.
Exercice 2 : Fichiers structurés en tableaux
Un fichier peut être organisé en un tableau de M blocs. le bloc constitue l'unité de transfert entre la mémoire principale et la mémoire secondaire. Une lecture est réalisée par l'ordre Lirebloc( F, I, Bloc) et une écriture par l'ordre Ecrirebloc ( F, I, Bloc) avec F le nom du fichier, I le numéro du bloc à lire (ou sur lequel on écrit) et Bloc la zone mémoire destinée pour les transferts). Chaque bloc peut contenir B articles. L'article est réduit à sa clé. Le fichier est trié. C'est à dire :
- à l'intérieur du bloc les articles sont ordonnés,
- tout article dans le bloc I est inférieur à tout article dans le bloc I+1 ( I=1, 2, .....M-1)
Dans un fichier organisé ainsi, on commence par faire un chargement initial de façon à remplir équitablement les blocs.( Par exemple si on sait que le nombre d'articles à ranger est 5000 et que chaque bloc peut renfermer B=100 articles au maximum, on choisit M = 100 et de cette façon les blocs sont remplis à 50% par ce chargement initial)
1. Ecrire l'algorithme de la recherche dichotomique.
2. Donner l'algorithme qui insère un article de clé donnée.
3. Afin d'éviter les décalages d'articles entre blocs (c'est à dire d'un bloc vers un autre) causés par une insertion, on peut utiliser une zone commune pour ranger les articles qui débordent de certains blocs. La zone commune est un autre fichier, un tableau composé de N blocs, qui peut alors contenir plusieurs listes. Chaque liste renferme les débordements d'un même bloc du fichier initial de données. On ainsi le schéma suivant :
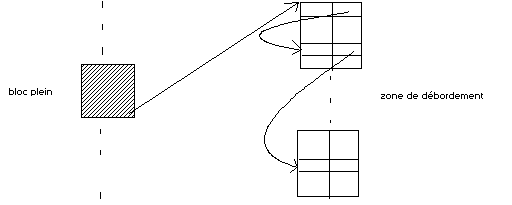
Fichier initial de données Fichier de débordements
a) Définir la structure du bloc du fichier et la structure de la zone commune (appelée aussi zone de débordements) .
b) Donner le pseudo algorithme qui recherche un article de clé donnée et qui l'insère s'il ne le trouve pas. On fera ressortir les principaux modules utilisés. Développer le module de recherche d'une clé dans le fichier de débordements.
* * * * *